
Corporate Sovereignty in the Age of AI
Washington demanded Anthropic switch off its best model for non-US users. But the AI stack offers surprising ways to maintain sovereignty away from AI models
Written on
The architecture behind ChatGPT was invented to translate — and that is the clue to defensible products. Pair an LLM's natural-language interface with machine learning's specialist analysis. But how do you tame hallucinations and industrialise it for thousands of users?

The potential of blending ML with AI is immense and largely unexplored.
Businesses can raise revenues and defend IP by developing products and services based on Machine Learning (ML) partnered with generative AI. Unique value to staff and clients arises when artificial intelligence is a natural language interface to specialist data and analysis generated by Machine Learning.
This blog follows ' Think Outside the Bot', which gives some concrete ideas for generating innovative products with AI.

Imagine the various AI technologies as elements of the mind working together.
LLM’s are akin to your intuitive mind, a collection of rules of thumb and context specific knowledge, also known as ‘common sense’. They are not your logical mind, they do not deduce cause from effect. In other words, they are Daniel Kahnemann’s ‘system 1’, “Thinking fast” as opposed to ‘system 2’ “Thinking slow”. Although we have ChatGPT as our intuitive AI, as yet, there is no logical AI, no causal reasoner.
Whereas, the machine learning systems are ancillary brain functions, providing services to the intuitive mind:
Video to Text
Text to Video
Text to Speech
Translation
Image segmentation
Object classification
Trend and feature extraction
Anomaly detection
etc, see Huggingface.co/models for the full range of tools.
The LLM’s, intuition, can be used to string together these other functions into a useful workflow.
What follows is not a grand unified theory of the AI+ML opportunity, but guiding thoughts.
The architecture behind Large Language Models (LLM), like ChatGPT, was invented to translate between languages. So when adapting LLM’s for new products or services, ask them to map from one domain to another, this is their raison d’etre. Their general knowledge and capacity for reasoning is a happy outcome of training at a grand scale, not a design feature of the architecture.
Instead, consider that LLM's happily learn to translate from natural language to any format of data or code. You may already use it to map from a draft text into a polished professional style. But it can be taught to map from a picture of a website to the code for that website. Or from natural language describing an object to a CNC routing plan for that object. These examples have been built, they are extensions of the ‘translation’ task.

AI is not yet truly creative. It tends to interpolate between existing styles and content rather than extrapolate into entirely new content. Although, even we humans rarely get to invent something entirely new, most of our efforts are simply interpolations between previous work and other people’s work.
All neural networks ‘learn’ within the data they are presented and are dubious outside that training set. GPT-4 is so good because it is trained on an enormous chunk of the world’s data. Very little falls outside its training set. But try asking it to be truly inventive, you will find it simply mixes existing ideas, it does not truly ‘create’.
Generative image models, like Midjourney or DallE3 are similar, they interpolate between existing styles and concepts very well. They use a latent space to do this, allowing them to mix different strengths of styles as if mixing a cocktail. That fixed latent space of possibilities is also what constrains them.

Modern AI architectures, inc most machine learning and language models, are driven by probabilities not a causal understanding of the world. LLM’s like ChatGPT are akin to a knowledgeable and eager new intern. They prefer to give a plausible answer to a direct question, even when they should say 'I'm not sure'. This leads to ‘hallucinations’, making stuff up.
People have this same weakness, so we as listeners learn to know when we can rely on any individual. Over time, both LLM’s and people become more reliable as their understanding grows. GPT4 is already less likely to make up facts than GPT3.5.
We can protect ourselves too, here’s how:
If the output to your problem can be represented in code, then there’s a chance that hallucinations can be identified and removed automatically.
Graphs, diagrams, maths, algorithms, business processes, data structures etc, all can be represented by AI in code formats. That code can then be tested to discover any errors, or hallucinations. The system can then be designed to rectify those errors.
We can add a reflection step into the workflow, formally asking the mode, or indeed another LLM entirely, to critique the output. Then ask the LLM to make improvements. We can repeat this loop, similar to me editing a blog article multiple times. Agentic AI, i.e LLM’s arranged as agents, can use self reflection and web searches to achieve ‘super human’ levels of fact checking, see https://arxiv.org/pdf/2403.18802.pdf
A third approach is to use specialist models, such as Perplexity. These combine traditional search technology with a LLM trained to summarise information and provide references from the search results. Those references cannot be invented, only selected.

Smaller models tend to be faster. This is especially true with the arrival of the Groq service for fast inference. The Groq service runs models similar to ChatGPT at such speed that we can consider generating many responses to a query then selecting the best.
Furthermore, with such speed we can employ the ‘society of mind’ approach, where an LLM critiques and improves its response with itself before delivering a final answer to a query. This gives the illusion of better considered responses from today's models.
Huggingface maintain a leaderboard of the open source models:
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard

Many projects are small, to be used by a small number of staff or clients. This is where we can experiment fast, deploy and iterate with only minimal levels of industrialisation.
As opposed to projects, products may be used by hundreds or thousands of users need more attention. Industrialisation is scaling up a service to handle this many users whilst adding to your reputation, not detracting from it.
Each one of the key ingredients for agents has implications for scaling up from a technology demonstrator to a hardened service.
LLM’s are generalised models but we want them to discuss only the task at hand, not offer their opinons on racy subjects. This requires guardrails and/or semantic routers. Beware, even guarded LLM’s can be cajoled into unguarded statements, just as an exasperated employee can.
LLM’s can be fine tuned for your uses. But beware this introduces new costs, OpenAI fine tuned models are triple the price of standard models. You may get more out of prompting strategies and clean data than fine tuning.
Data makes the agent useful, but we don’t want to share too much information with the user. The classic example is a HR chatbot which discusses other people’s records. This would not only be embarrasing, but in contravention of privacy regulations.
Even for non personal applications we face PII (privately identifiable information) problems. Some data will inadvertently contain PII or copyright material which must be cleaned before being provided to the LLM. OpenAI may be able to defend copyright claims, but can you?
PII is also an issue when chatting with staff and customers. Be sure your bot gets their GDPR approval first, or whichever legislation is relevant to the jurisdiction.
Some data is unfriendly to LLM’s. For example, LLM’s struggle with interpreting jagged tables in word, excel and PDF’s. Other data contains images and diagrams which are not worth asking LLM’s to interpret. This all needs preparation, eg via services like unstructured.io
Will users be authenticated? If so, how and what data should we store on them?
Should data provided to/from the LLM be secured both at rest and in transit? How will updates/additions/deletions of that data be made without impacting the live system?
Will the company and users tolerate their data being passed to an LLM hosted by a third party, such as OpenAI, Google or other? If not, then the LLM must be hosted locally or within the same cloud tenant (see Azure OpenAI). This introduces new costs.
Audit trails of every conversation will also be necessary wherever accusations of misrepresentation, bias, copyright transgression or other liability could be made.
Washington demanded Anthropic switch off its best model for non-US users. But the AI stack offers surprising ways to maintain sovereignty away from AI models

Anthropic measured something like emotions inside Claude — not mimicry, but representations that direct it. Intervene and the behaviour changes. The debate fixates on one question: is AI conscious? This suggests both sides ask the wrong thing. What does it mean for business?
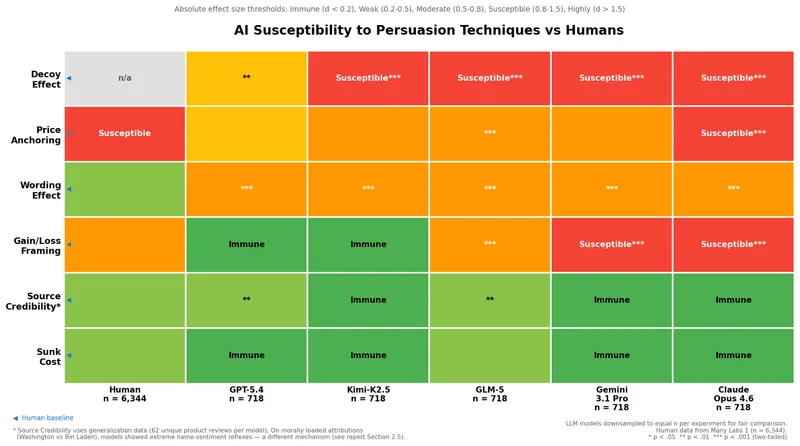
Gartner says a third of enterprise software purchases will involve an AI agent by 2028, and machines are assumed immune to persuasion. We ran 8,000 trials across five frontier models. Which techniques work, which backfire, and what does that mean for selling to agents?