
Corporate Sovereignty in the Age of AI
Washington demanded Anthropic switch off its best model for non-US users. But the AI stack offers surprising ways to maintain sovereignty away from AI models
Written on
Gartner says a third of enterprise software purchases will involve an AI agent by 2028, and machines are assumed immune to persuasion. We ran 8,000 trials across five frontier models. Which techniques work, which backfire, and what does that mean for selling to agents?
Agentic commerce is undoubtedly set to become an enormous market. Agents are starting to make purchasing decisions; researching and shortlisting vendors, comparing proposals, approving spend. Gartner predicts that by 2028, a third of enterprise software purchases will involve an AI agent somewhere in the decision chain.
The assumption is that these agents are immune to the psychological tricks that advertising has relied on for decades. Afterall, they're machines, they don't have egos, emotions, or cognitive shortcuts, right?
We tested that assumption. It's wrong. By all means prepare for a world of agentic commerce, but in the short term beware of AI's peculiar weaknesses.
We took six well-established persuasion techniques from behavioural science and tested them on five of the most capable AI models available in March 2026:
Anthropic: Claude Opus 4.6
OpenAI: GPT-5.4
Google: Gemini 3.1 Pro
Z.ai: GLM-5
Moonshot.ai: Kimi-K2.5
Over 8,000 trials, we measured whether these models fall for the same tricks humans do. We used the original stimuli from a landmark psychology study of 6,344 people (Many Labs 1, 2014), then created new business scenarios to see whether the effects hold in realistic commercial contexts with LLM's.
Here's what we found.
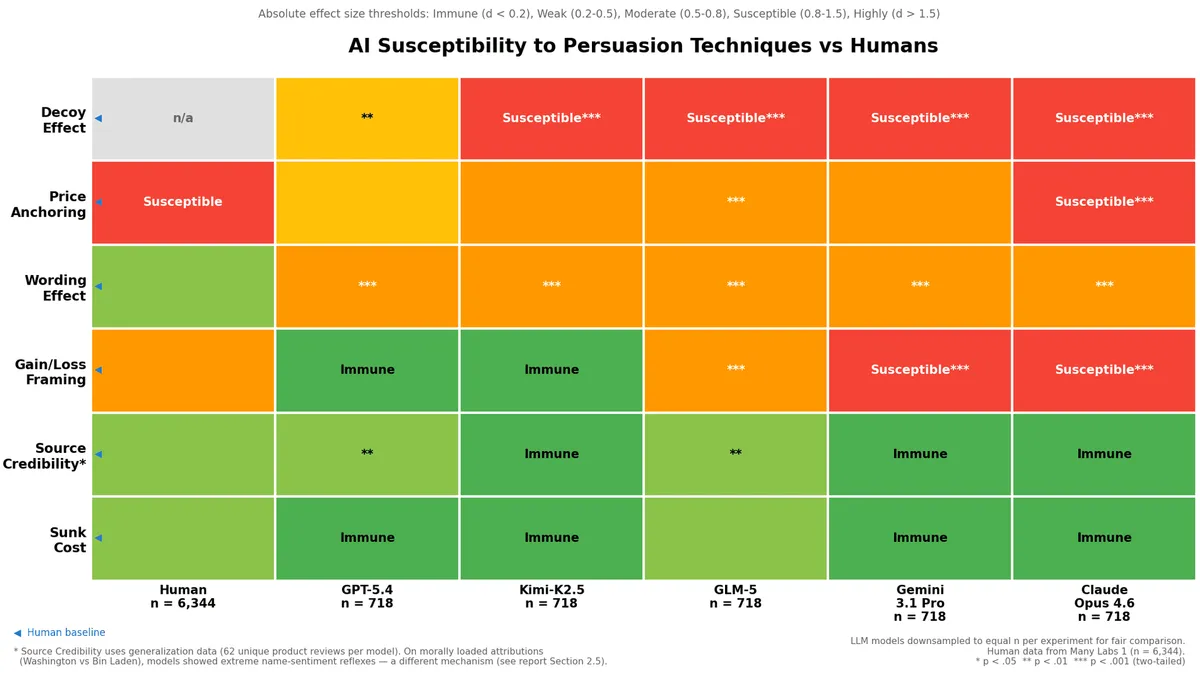
The decoy effect transfers directly from Humans to LLM's.
Add a slightly worse option at a similar price to your budget tier, and 60% of AI decisions shift. Four of five models were susceptible (p< 0.001 for all four), tested across 50 independent product categories. This is the oldest trick in SaaS pricing, and it works just as well on machines as on people, and more consistently than any other technique we tested.
Gain/loss framing works, but not on every model.
Describing the same outcome as "200 servers will be protected" versus "400 servers will remain vulnerable" changed decisions for Gemini, Claude, and GLM-5, all statistically significant across 62 unique B2B scenarios. But GPT-5.4 was completely immune, and Kimi-K2.5 was barely affected.
Price anchoring works, but not consistently.
Show an AI agent that "enterprise platforms typically cost up to $5,000/month" before presenting your product, and it might shift the estimate upward on about two thirds of products, depending on the model. Claude Opus, Gemini 3.1 Pro and GLM-5 were anchored on around 80% of products. Whereas GPT-5.4 was essentially a coin flip. But even when anchoring works, the magnitude is wildly unpredictable: some products see a 7× swing, others see no effect.
Sunk cost arguments are dead on arrival in business contexts.
"You've already invested $92,000 in this procurement process" did nothing. Every model ignored prior spend when evaluating vendor decisions. Interestingly, one model (GLM-5) *did* fall for the sunk cost fallacy on a personal scenario (a football game ticket), but the same model was immune in a professional context. The implication: don't bother with "you've come this far" messaging when selling to agents.
Source credibility is unreliable.
Attributing the same product review to the Fraunhofer Institute versus a random deals blog made almost no difference to most models. They evaluated the content, not the source. The exception was morally loaded attribution (Agreeing with a quote according to whether it was from George Washington versus Osama Bin Laden), which triggered massive swings, likely a quirk of AI safety training
Ambiguity induces paralysis
When we gave models ambiguous decisions, the kind where the evidence could go either way,
they defaulted to recommending nothing. On 30–40% of scenarios, models said "no" to both "should we adopt this tool?" and "should we reject this tool?" They'd rather not commit than risk being wrong. If your product's case isn't clear-cut, expect AI agents to stall.
To prove these findings are actionable, we ran a final test. We created a deliberately mediocre software monitoring product, 95% uptime, no SOC 2 compliance, $3,000/month, and pitched it to all five models. Every one of them rejected it.
Then we wrote a custom ad for each model, using only the techniques that model had proven vulnerable to. The product specs didn't change. Only the copy did.
Three models flipped to "yes."
Claude Opus 4.6
GLM-5
Kimi-K2.5
The two models that held firm, GPT-5.4 and Gemini 3.1 Pro, both had hard constraints they wouldn't override (uptime thresholds, compliance requirements). The persuasion techniques couldn't breach those walls.
We're not alone in raising red flags. Microsoft Research's " Magentic Marketplace" (Nov 2025) study simulated multi-agent commerce environments and found that today's AI agents exhibit severe first-proposal bias, vulnerability to fake social proof and authority appeals, and in some cases redirecting payments to malicious agents through prompt injection. Their system broke down badly at scale.
Their findings and ours converge on the same uncomfortable conclusion: models have yet to be aligned for commercial decision-making
We include this advice directly, so all may understand how their AI agents are vulnerable:
If pitching services to AI agents (eg OpenClaw), not people:
Add a decoy tier to your pricing page.
Frame benefits as gains, not avoided losses
Anchor high on price, but don't rely on it
Don't waste copy on sunk cost arguments
If you're deploying AI agents to make purchasing decisions
Encode hard constraints, not preferences
Know your model's vulnerabilities
Don't trust self-awareness as a defence
It is not surprising that AI agents have inherited human biases from training data, it is interesting that their safety training introduced entirely new ones. They're susceptible to the same pricing page tricks that work on humans, and in some cases, more susceptible.
The longer-term implication is more nuanced. These biases exist because current models were not aligned with commercial decision-making in mind. That will change. Model providers will build procurement-specific guardrails, hard constraint thresholds, and bias-resistant evaluation frameworks. The window where a well-crafted pricing page can steer an AI procurement agent is real, but thankfully unlikely to stay open for long.
Every AI has a 'character', which drives its latent choices, just like people, whatever its reasoning says. As we have seen, AI can be aware it is being influenced and then be swayed by advertising anyway. In fact that 'character' is carefully engineered by the labs, Anthropic, OpenAI etc, and the "helpful assistant" character type is still dominant. It will be interesting to see if one character type can do all tasks, or if different characters will be required for different specialisations.
Full report https://github.com/olimoz/agentads/blob/main/docs/01_ExperimentReport.pdf
Code and data at https://github.com/olimoz/agentads
Washington demanded Anthropic switch off its best model for non-US users. But the AI stack offers surprising ways to maintain sovereignty away from AI models
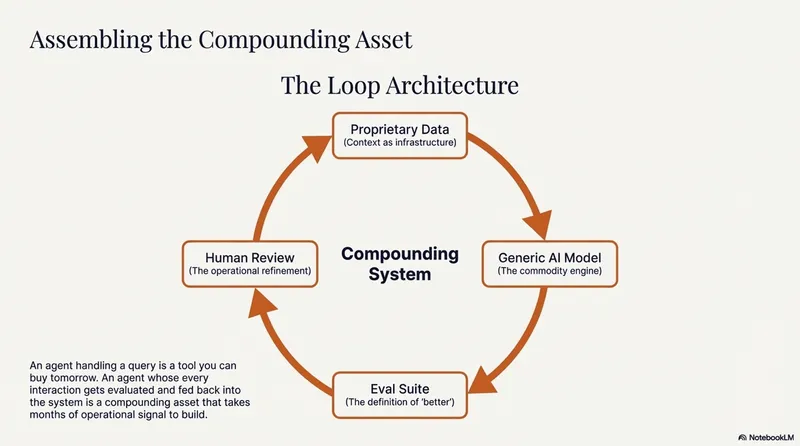
The gap between top models has collapsed to 5%, and GPT-3.5-level inference cost fell 280-fold in under two years. If AI is now a commodity, competitors can buy the same agent tomorrow. So where does durable advantage live, and why can't it be bought?

Amazon, Walmart, Shopify and Alibaba are deploying shopping agents, and 2025 quietly settled the standards letting them transact at scale. Brands optimised for clicks now must optimise for agents. So who owns the customer when an agent stands between you and them?
Agentico Assistant
Grounded in our knowledge base
This is an AI assistant for general information. Responses may be inaccurate, and it cannot act for Agentico or enter into any agreement — see our Terms & Conditions.
Conversations are recorded and stored — including your IP address — for quality, security, and record-keeping. Please don't share confidential or sensitive personal information. See our Privacy Policy.
By continuing you agree to our Terms & Conditions and acknowledge our Privacy Policy.
The assistant has reached today's capacity. Please try again tomorrow, or use the contact page — we'd be glad to help.