
Corporate Sovereignty in the Age of AI
Washington demanded Anthropic switch off its best model for non-US users. But the AI stack offers surprising ways to maintain sovereignty away from AI models
Written on
The gap between top models has collapsed to 5%, and GPT-3.5-level inference cost fell 280-fold in under two years. If AI is now a commodity, competitors can buy the same agent tomorrow. So where does durable advantage live, and why can't it be bought?
Fastest learner wins. Eric Schmidt - Ex CEO of Google.
Eric wasn't talking about any single AI tool. He was talking about what happens when AI agents, software that acts on your behalf, learn from every interaction and get measurably better each time. The firms that build those feedback loops close the gap between action and insight fastest. The agentic era makes that possible at a speed and granularity that simply wasn't available before.
AI is a commodity. The Stanford HAI AI Index 2025 documents how similar models have become. The gap between the highest and 10th-ranked models dropped from 12% in 2024 to just 5% by early 2025.
The cost trajectory is even more dramatic: the cost of querying a model at GPT-3.5 performance fell from $20.00 to $0.07 per million tokens between November 2022 and October 2024, a more than 280-fold reduction in under two years. This is not a pricing anomaly. It is a structural shift.
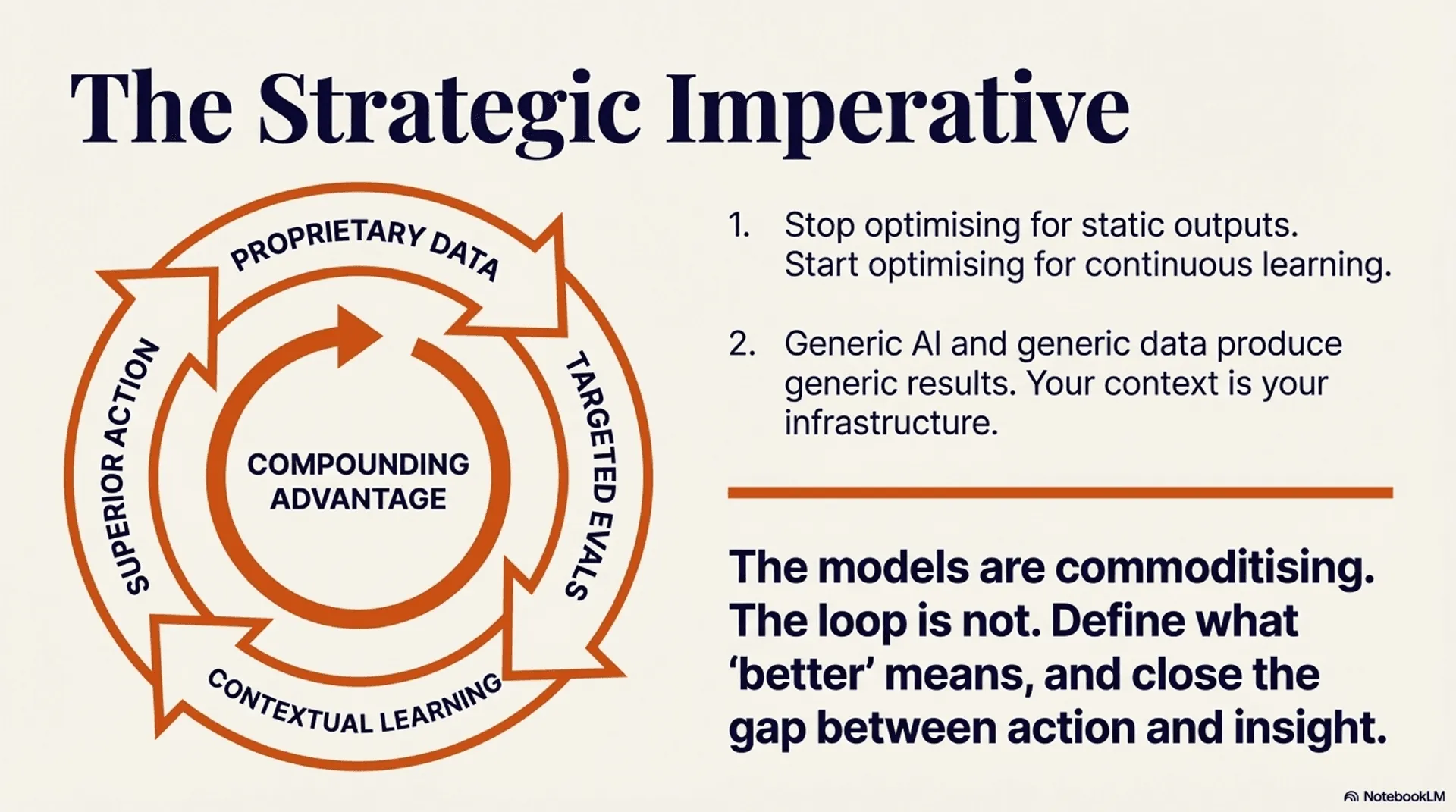
Generic AI on generic data produces generic outputs. The question isn't "are we using AI?" It's "are we feeding it anything our competitors cannot?"
Data is the foundation. Learning loops are the mechanism that activates it. And when the loop is genuinely tight something larger emerges: a system that becomes substantively better the more it is used, in ways that are proprietary to you.
We've discussed how context becomes infrastructure in detail.
Ethan Mollick, Professor of Innovation at Wharton Business School names the failure mode precisely: "If the output is what matters in your business, you're in trouble. If the process matters, the conversations, the writing of the report more than the report itself, then there's hope."
Most organisations deploying AI right now are optimising for output. Better reports. Faster summaries. The ones building moats are asking a different question: does every interaction make the next one better? Is the system learning? And — this is where it gets hard — who owns the definition of what "better" means, precisely what does good look like?
That's what the AI industry calls 'evals', short for simple evaluations that can be automatically be run on the AI's performance.
OpenAI frames them as the natural successor to OKRs and KPIs. Evals are the extension of measurement for the AI era, and robust evals create compounding advantages and institutional know-how as systems improve.
Bessemer Venture Partners are more direct: instead of chasing leaderboard scores, the companies pulling ahead are building internal eval suites grounded in their own data.
Tobi Lütke at Shopify has pushed this into his entire organisation, teams must demonstrate why AI can't do something before asking for headcount. To demonstrate whether AI can't do something requires an eval.
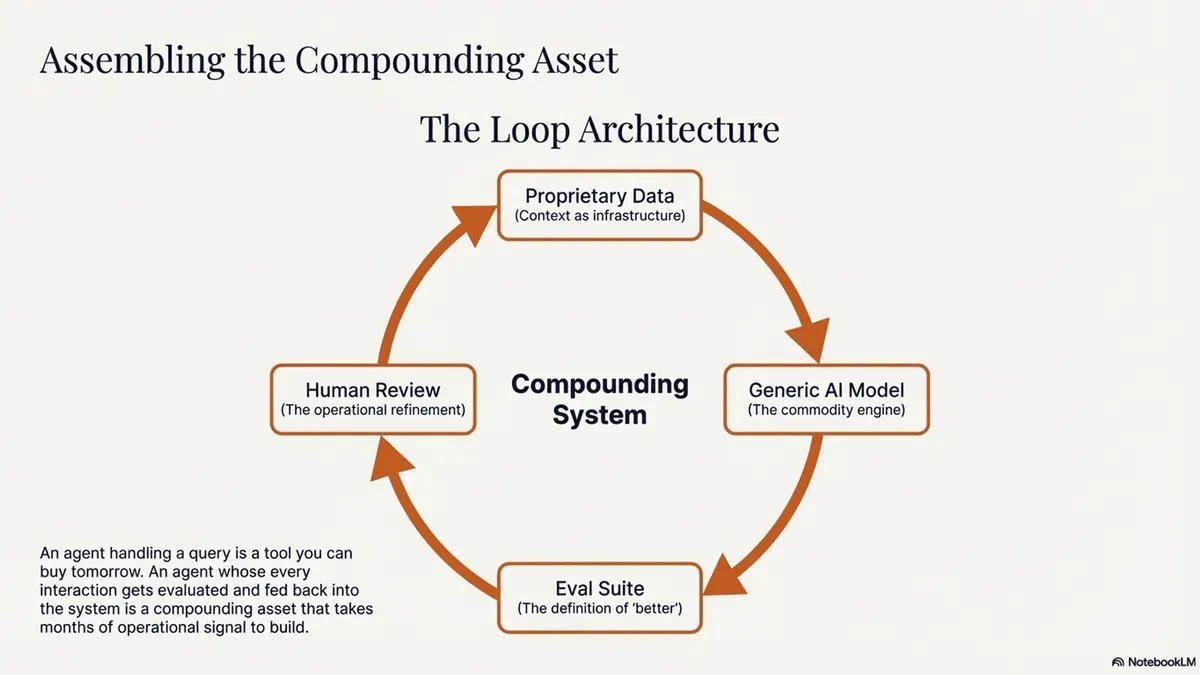
An agent that handles a customer query is a tool. An agent whose every interaction gets evaluated, feeds back into the system, and makes the next interaction sharper is a compounding asset. The former your competitors can buy tomorrow. The latter takes months of operational signal to build — and every day the loop runs, the gap widens. Its worth having because its hard to do.
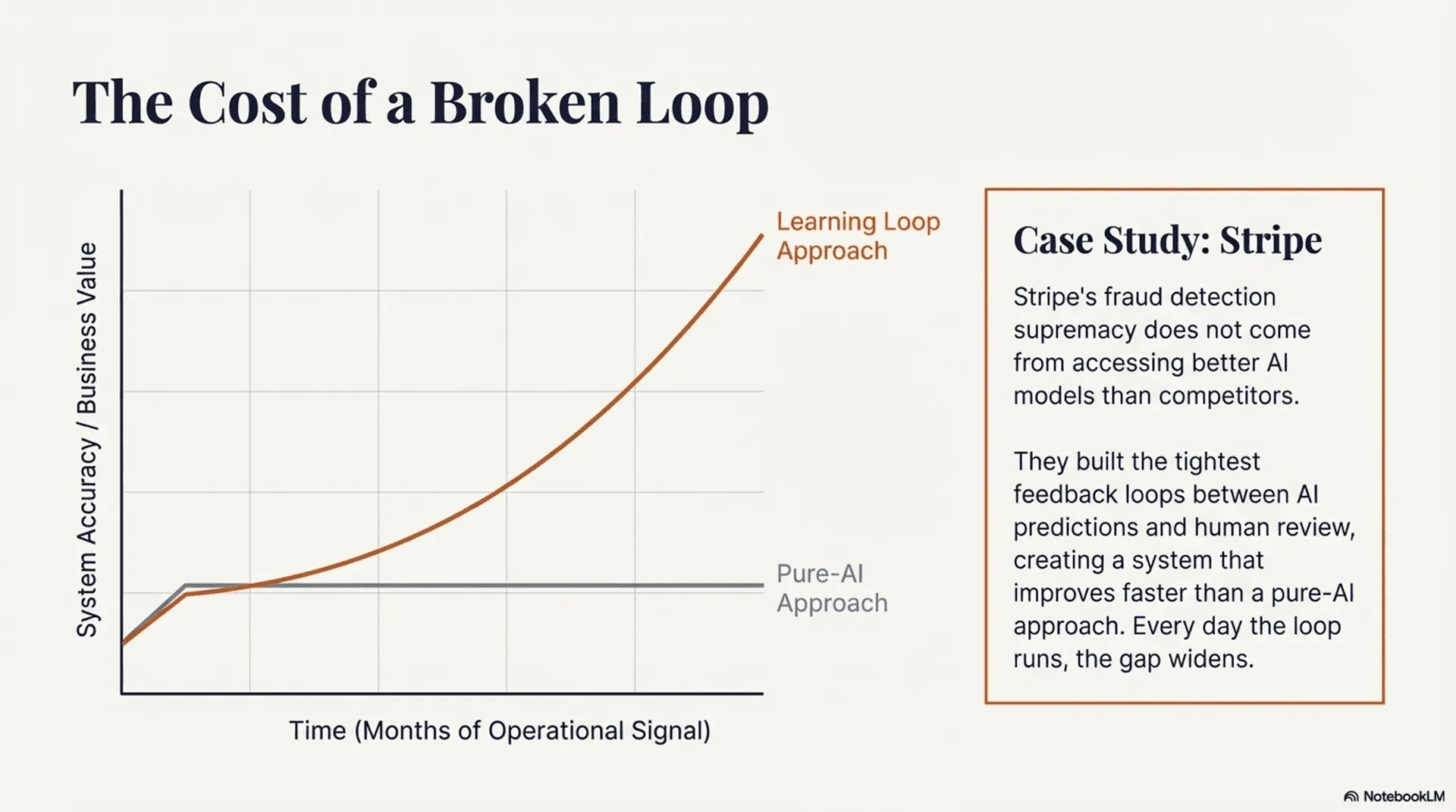
For example, Stripe's fraud detection isn't superior because they have access to better AI models than their competitors. It's superior because they've built the tightest feedback loops between AI predictions and human review, creating a learning system that improves faster than pure-AI approaches.
McKinsey research found that high performers are nearly three times as likely to have fundamentally redesigned individual workflows rather than simply layered AI onto existing ones. Deployment without redesign produces no compounding.
The moat is not the agent. The moat is how well the agent specialises to create value.
| | | | | --- | --- | --- | | Moat | What it is | What it isn't | | Proprietary data | Operational signal only your context generates — customer interactions, domain feedback, process outcomes | Feeding AI generic or public data your competitors can access on the same terms | | Learning loops | Every interaction improves the next one; usage and learning are the same motion | Deploying AI for static outputs — same quality month on month, no signal feeding back in | | Evals | A defined, ongoing measure of what "better" means — the instrument that closes the loop | Measuring success by sentiment or cost saved, with no mechanism to know if the system is actually improving |
If the learning loop sounds abstract, consider who is investing in it at the frontier.
Meta's FAIR lab published HyperAgents in March 2026, pushing the idea further: agents that can modify not just how they perform tasks but how they improve. Tested across coding, academic review, robotics, and mathematics, the system autonomously developed its own performance tracking and persistent memory — capabilities nobody programmed in. The meta-level improvements transferred across entirely different domains. This is a learning loop that compounds aross contexts, not just within them.
OpenAI's own Codex team published their findings on building a million-line application with zero human-written code. Their core lesson was not about model capability. It was about feedback infrastructure: encoding "golden principles" into the repository, designing the system so that human judgement feeds back in continuously. Every review comment, every bug, every refactoring PR becomes signal that makes the next agent interaction better. That is the learning loop made operational.
For you or I there are already projects which demonstrate how it works in business agents and science:
Nous Research's Hermes Agent builds learning loops into a general-purpose agent: it creates skills from experience, improves them during use, and accumulates context across sessions. It even compresses interaction histories into training data for future models — a loop feeding a loop.
Andrej Karpathy's autoresearch (60,000 GitHub stars in its first weeks) is a distilled version of the pattern. An AI agent modifies code, trains for five minutes, evaluates whether the result improved, keeps or discards the change, and repeats. You sleep; it runs a hundred experiments. The architecture is deliberately minimal.
These are not side projects. They represent where the most capable AI researchers in the world are directing their attention. The pattern they are all converging on — propose, evaluate, learn, repeat — is the same one available to any organisation willing to define what "better" means for their own processes. The models are commoditising. The loop is not.
How to Easily Sway AI Into Buying...
Washington demanded Anthropic switch off its best model for non-US users. But the AI stack offers surprising ways to maintain sovereignty away from AI models
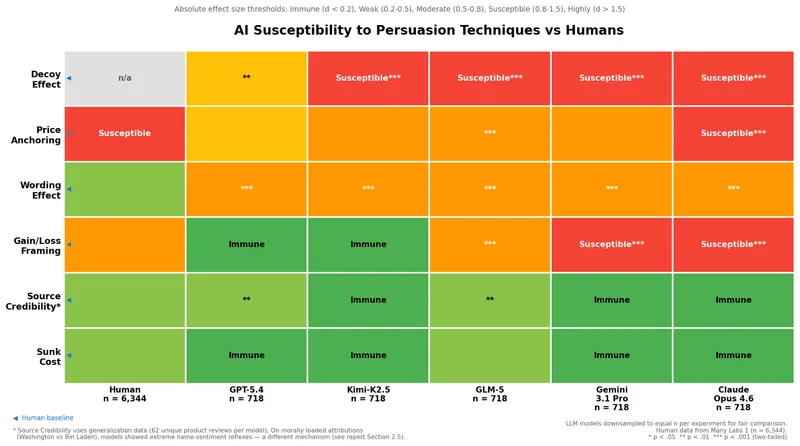
Gartner says a third of enterprise software purchases will involve an AI agent by 2028, and machines are assumed immune to persuasion. We ran 8,000 trials across five frontier models. Which techniques work, which backfire, and what does that mean for selling to agents?

Berkeley's second Agentic AI Summit drew Google, OpenAI, NVIDIA, IBM and frontier researchers for talks on where agents are heading, from Chi Wang's MassGen to the Linux Foundation's 'Internet of Agents'. So what does the near future of agentic AI actually hold for enterprises?